
TL;DR — A good user story can be estimated. We don’t need an exact estimate, but just enough to help the rank and schedule the story’s implementation.
If the above TL;DR sounds familiar, it’s because it’s practically an exact quote from Bill Wake’s 2003 blog post that introduced the INVEST approach to product backlog items. And sure, while there has more recently been some introspection among the product management community among estimates v. #noEstimates camps — for today — I ask that we put aside our religious differences and talk about how you can prepare Product Backlog Items (PBIs) for the backlog refinement process.
As a refresher, the Agile Alliance defines the refinement process as:
“… when the product owner and some, or all, of the rest of the team review items on the backlog to ensure the backlog contains the appropriate items, that they are prioritized, and that the items at the top of the backlog are ready for delivery. This activity occurs on a regular basis and may be an officially scheduled meeting or an ongoing activity.”
Personally, I find the PBI a powerful communications tool that helps me build relationships with customers, stakeholders, and teams, especially when elevating the conversation on feature sets past the abstraction of story points, and hopefully, past the sole focus on “When can you get this done?”
Below is an approach that I’ve found just large enough to scale, yet just small enough to identify size in the context of value delivery without the process abandonment that comes with overly-Byzantine estimation processes.
Setting up the PBI for Sizing
Great discussions on delivering valuable features begin with PBIs that address, at a minimum, the following:
- The User Story
- Description
- Acceptance Criteria
Let’s briefly go into detail of each, keeping in mind that the goal here is to stand-up a PBI that is estimable, that is, equipped with just enough information so it’s ready for refinement, sizing, then development, and finally delivery.
The User Story
You won’t go wrong if you confine your user story to a single sentence to answer the question, “What problem or pain point are we trying to address, and for whom?”
There is plenty of digital ink on this topic, many offering something formulaic, like this template by Mike Cohn of Mountain Goat Software:
As a < type of user >, I want < some goal > so that < some reason >
This is not a bad pattern to follow. However, I’ve personally seen this template trip up less mature teams and/or product owners more than once.
As an example of what I’m talking about, let’s imagine I’m a newly minted product owner for an up-and-coming blogging platform, Tedium.com. Not long after I get started, I introduce a potentially problematic PBI leading off with a user story that reads:
As an end-user, I want the application to support table tags so I can put in Excel data.
First, we have no real picture of who the end-user is, let alone any empathy for wanting to use such a crufty HTML tagging idiom as the <table /> tag. Second, we unintentionally shift the focus onto the implementation versus solving the underlying problem.
How might I render the same user story?
As Dahlia the Data Scientist, I need to be able to communicate data sets in rows and columns.
By asserting a previously shared user persona and removing specifics about the implementation, we’ve not only injected a bit more empathy, but we also keep the discussion more focused on addressing the underlying issue.
Any more details can be fleshed out in the ‘Description’ section of the PBI. Feel free to read my blog post on persona creation at your leisure.
Description
Continuing with our ‘Dahlia’s data dilemma’ example, let’s explore how we might articulate an aggregate of conversations describing the problem we’re trying to solve:
TL;DR: What we’re being asked is to do is make our story edit feature more valuable to science, technology, engineering, and math bloggers who want and need to cut-and-paste rows and columns of data from popular spreadsheet applications.
Conversations: In a Skype session with Dahlia, Chief Data Scientist at DYI Analytics, she expressed quite a bit of frustration that she was unable to simply and quickly introduce examples of data she cut and pasted from Excel. Instead, she finds herself having to painstakingly input spaces between fields to get a ‘columns-like’ effect, which works fine until the user visits her page from a tablet or mobile device. See the attached meeting video. The pain begins at the '3:24 mark'. Looking in our customer request backlog, it appears we have several similar requests from individuals using Excel, Google Sheets, and/or LibreOffice. I have attached examples from each of these products, along with a link to our UX style guide for rendering tabular data. FYI: In a quick hallway chat with our lead architect, it seems all we’re really being asked to do is extend our blogging editor to accept a paste of one or more lines of data, where each line contains fields delimited by tabs, and render the information in a row/column tabular format in the blog post.
It’s been my experience that the most successful PBIs I’ve provided a team have not been those I’ve laboriously wordsmithed to perfection, but rather those that accurately aggregate conversations that address a multitude of questions, such as:
- What is the current customer experience without the requested feature?
- If they are engaging in a workaround, how tenable and scalable is it?
- Are there screenshots, recordings, data files and/or other artifacts that can help provide additional insights?
- Will we run into any potential SLA, regulatory compliance, operational, security, and/or other such problems if we don’t deliver the feature?
- Do we have any references to existing tooling, modules, libraries, or other resources that might help meet the customer’s need and/or deliver the desired solution?
While I did offer just a little bit of technical ‘how’ at the very end of our example description, it was just enough to serve as a relevant talking point for the team as they engage in sizing the PBI.
Guardrails (optional)
Totally optional, but something I discovered more recently helps product owners work with teams to create, split, and more accurately estimate stories is:
- a simple enumeration of the things that the story will address;
- sometimes items of that will be addressed in upcoming sprints to nudge the solution to perfection;
- what ‘might’ be addressed in the distant future after significant user data and feedback is collected;
- what absolutely will NOT be addressed in the solution;
- various, specific implementation preferences the engineering team prescribes during the estimations and sprint planning conversations.
Acceptance Criteria
Another PBI pitfall I’ve observed is in the area of acceptance criteria. Either they are one line wonders, or they wind up as exhaustive software requirements specifications. Both approaches are fraught with peril as the former doesn’t convey how you’re going to sign off on the work, and the latter can lead less experienced engineers to code at “the letter of the law” rather than to “the heart of the solution.”
A middle ground that I’ve found works well is to render the acceptance criteria using a ‘Gherkin/Cucumber’ format. Below is yet another example based on our cut-n-paste tables for Tedium.com use case:
Scenario 1:Paste in the data on Edit
Given I have copied a set of rows and columns into my
clipboard from a spreadsheet tool such as Excel,
Google Sheets, and/or LibreOffice
When I paste the copied rows and columns into the blog editor
Then I should see my data entered as rows and columns
Scenario 2:Render the data on Publish
Given I have previously and successfully cut and pasted
in rows and columns of data
and I have previously and successfully saved my cut
and pasted data
When I publish my blog post
Then I should see my data rendered as rows and columns
Again you might notice that I’ve avoided specific implementation details as much as possible. One thing you won’t see from the above example are those instances when I craft the acceptance criteria first, in response to writer’s block issues with the user story or details.
Prepping the PBI for Prioritization
We’ve got enough now for a team to size a story, but we don’t really offer anything that helps the team, nor the business for that matter, understand how these PBIs stack-rank in relation to one another.
So again, here’s an approach I use to stack-ranking PBIs using just enough process to avoid abandonment that comes with more complex approaches.
Business Value
Before we can prioritize PBIs, we need to assign them a business value. Unfortunately, I’ve seen this particular input suffer some of the same fates as the acceptance criteria. That is, I’ve witnessed Business Value abandoned either because it is a single field devoid of any context, or an impossible amalgamation of a dozen or so KPIs copied from Salesforce.
The middle ground I might suggest is the sum of three general measures, each representing a different key area of your business. It can be any three that give you this 30k foot view, but here are 3 for free to get you started:
- Feature Usage
- Revenue Impact
- Operational Concerns
Let’s quickly unpack each of these with the understanding, that over time, you’ll get better at these as you grow into your organization.
Feature Usage
This metric answers the question, “Will this feature increase or decrease engagement within a particular module, mechanism, or workflow within our product?”
There are many sources you can pull from to gather this information, including analytics/performance monitoring platforms such as Application Insights, customer service systems such as Service Now, and feature adoption tracking services such as Pendo.io. Don’t forget to talk to customers so you can add important context to said quantitative measures with qualitative feedback.
Revenue Impact
This measure addresses the concern, “Will this feature have an impact on expanding the customer base, or will it contribute to churn?”
A great place to harvest this information is via CRM systems such as Salesforce or Dynamics 365. Your customer request backlog can similarly contribute insights. It also doesn’t hurt to have conversations with sales, marketing, and account executives, when it comes to this metric.
Operational Concerns
This business area responds to inquiries along the lines of, “Does this feature reduce or increase cloud costs, will it alleviate concerns over security and compliance, can it reduce bug volume and incident closure times, and does it improve or decrease uptime and system responsiveness?”
If a penny saved is a penny earned, then let’s go ahead and take into consideration technical debt retirement, response times, reductions in service provider costs, and/or the awesomeness of implementing integration automation. This also helps avoid fines and penalties by proactively avoiding issues often associated with security and compliance concerns.
You may be surprised just how receptive and chatty DevOps, InfoSec, and CS engineers become when you invite them into the conversation.
Calculating the Aggregate Value
I know, nobody said there was going to be math, so I’ll keep this simple, especially as I’m writing for the benefit of someone just starting out, or a veteran PM simplifying their business valuation process.
Let’s start out with this formula:
Business Value = (Feature Usage + Revenue Impact + Operational Concerns)
Now let’s define a range of the summed values:
Net Negative Impact == 1
Neutral Impact == 2
Net Positive Impact == 3
So let’s see an example of how this might work out for a product person at Tedium.com looking to prioritize PBIs prior to backlog refinement:
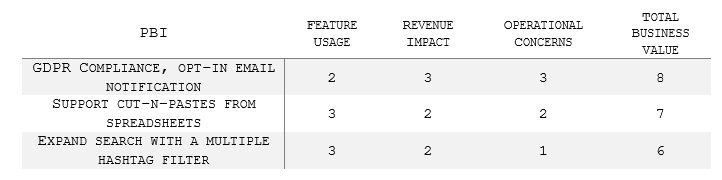
What we discover is that while GDPR compliance not only has a net positive impact on operational concerns as expected, surprisingly, it also has a positive impact on revenue, as the feature addresses objections surfaced in recent RFPs. As a result, we may want to focus on this PBI first.
Rules of the Road
Keep in mind that though I prefer Agile to other processes, I’m no ‘hyperscrumdamentalist.’ This is because much of what I do needs to be flexible enough to respond to whatever product context I’m dropped into … and resilient enough to accommodate those times the business introduces a “need to get ‘X’ done to keep the lights on” work item.
Put another way, as your teams grow in self-organizing maturity, the less they may find value in engaging in the above processes in such detail. So while your approach to product management and/or Agile may vary, please feel free to mix, match, and modify any of the above guidelines to more your PBIs closer to backlog refinement.