
I was asked an interesting question the other day: “Given what you’ve learned about search, natural language processing, & machine learning, how would you approach a new search project from the ground-up?”
Great question, and now that I’ve had a couple days to think about what I’ve learned across 3 separate search initiatives, here are some preliminary thoughts on how I might make the product management magic happen … articulated in this post across 4.5 topic headers … and hopefully executed as concurrently as possible.
1 — Listen, Observe, Rinse, Repeat
You can pretty much make bank that my reply to ‘which technology’ questions such as “What do you recommend, Elastic, Solr, Azure Search, or build your own search engine atop Lucene?” will usually be something along the lines of:
“It depends on the problems we’re trying to solve, and the context in which we’re solving them.”
I know this kind of answer drives executives nuts, and while it is important I bring my experiences into the mix, it is equally important that I don’t overlook value opportunities by introducing my personal biases. Especially in a situation where I’m being asked to deliver on an enterprise-scale, AI-assisted, full-text, digital assets search experience from the ground up.
This is why the first thing I want to do it listen to as many customers, end-users, stakeholders, technical, and developer people as possible.
What I hope to end up with are shareable artifacts in the form of powerful personas, insightful user journeys, and an understanding of the applications, business verticals, and operational issues that will all have an impact on the solution’s continuous delivery evolution.
Next, and of equal importance to me, is to collect data … lots and lots of data. Specifically, I want to get an idea of both the type and volume of documents users want and need to search. I’d also want to see if there’s analytics data revealing usage patterns just in case there are any surprises in what the users say versus what they actually do.
Third, I’d want to step back and take a 30-foot view of the interviews notes, user journeys, documents, search, and analytics data and see if we’re not missing anything in the larger ‘Information Search Process’ picture as defined by experts such as Marti Hearst and Carol Collier Kuhlthau.
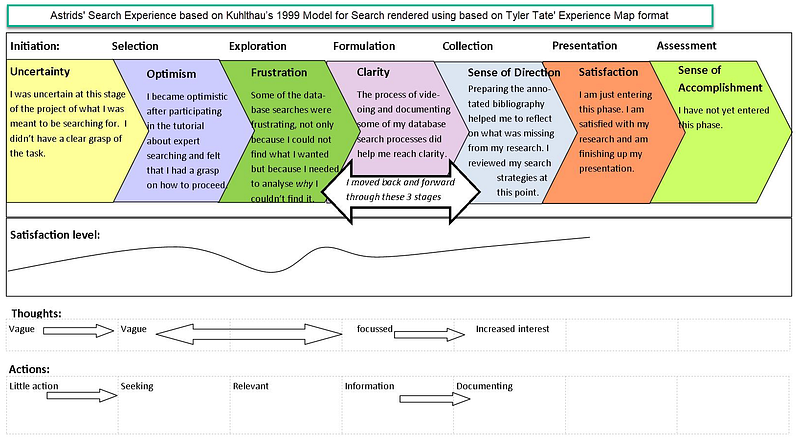
Astrids’ Information Search Experience
based on Kuhlthau’s 1999 Model for Search rendered using based on Tyler Tate’ Experience Map format
Usually, this process shakes out some gaps that require additional interviews, stakeholder conversations, and data collection.
2 — Identifying the AI Opportunities
Shortly after we get the ball rolling with conversations and data mining, I also want to begin identifying use cases within the user journeys that point out tedious repetition, ridiculous acts of remembering, and/or overwhelming calculations that avail themselves as AI opportunities.
Here is a hypothetical progression of such use cases derived from a multitude of user journeys involving searching and interrogating digital assets:
- Identifying copies and/or very similar content across a multitude of storage solutions. For example, imagine a situation where a large organization is working with contractors, the latter of whom to provide creatives for the former’s marketing campaign where they need to find the same — or worse — multiple versions and renditions of the same documents spread across DropBox, Google Drive, SharePoint, and local hard drives.
- Now imagine what happens when you not only need to find which of these document require content updates and subsequent review annotations in response to GDPR like regulation but also figure out which version of these is the current source of truth.
- Then imagine what pain points pop out when compliance and auditing issues occur when you’re asked to tie related assets together, you know, like the slogan on a banner ad originally extracted from a larger word document, or a 15 second YouTube promo ripped from a half-hour sales presentation video.
- If that’s not enough, then there’s an ask for smarter query responses by the parsing of question-like inquiries … and their contextual intent … because we know we want to support searches from mobile devices and virtual assistants.
- Finally, we’re pitched yet another curveball, an ask to both identify trending content in the context of the corpus over the past month, while simultaneously spotting troublesome text updates over the past week where outliers pre-empt problems such as a mislabeled brand.
And now perhaps you understand why its good to park one’s biases, as said combination of scenarios — when seen from the larger picture — indicate the potential need for a search solution that may also need to support both supervised and unsupervised machine learning methodologies.
3 — Build-Measure-Learn
There’s no reason why I can’t begin to launch experiments shortly after I’ve started to engage in conversations, data mining, and AI Exploration activities. Even if they are initially low-res mock-ups, ‘pretotypes,’ or since we’re working with content, brutally Spartan text dumps derived via calculations and/or tests.
The point here is not to build the product at this time, but rather get feedback of what is valuable, and if possible, an idea of how valuable it is in relevance to other value discoveries.
As time progresses, we can then begin to field more interactive solutions, hopefully with feature toggles and analytics tooling to help us launch an early adopter program … even in, and perhaps especially in a large enterprise setting.
One example might be a plan to first focus on supporting searches of existing text transcripts from podcasts to see if there is value here before simply leaping into the complexity and expense of speech-to-text integration.
Similarly, you may want to first limit your AI efforts to natural language processing approaches, and within that scope, further narrow the focus by first exploring bag-of-words capabilities baked-into the search technology before going down the path of building your own bi-gram indexer.
All the while, you want to continually meet with customers, collect usage and adoption data, and adjust as needed.
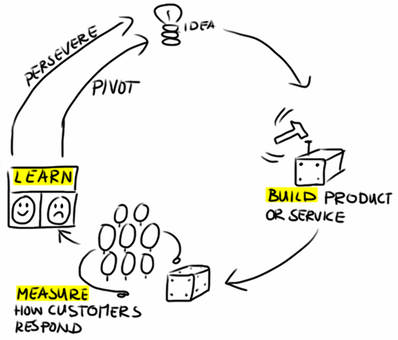
Once we have the initial feature set out, then it’s time to move to an experimentation strategy that is tactically facilitated using feature toggles. This then gives you opportunities to engage in statistically significant A/B tests, learn from Canary launches, and other stuff people like Netflix and Esty do when they launch thousands of features a day.
4 — Roadmap to Phoenix
Around the time we’ve started to engage your low-res experiments, we need to also start having conversations with the technical stakeholders. These individuals are the key difference between fast, measurable, continuous delivery versus a valueless, soul-crushing death march.
Here is where experience — sans bias — has its advantage, as we have survived enough mistakes to ask important questions such as:
- What type of immediacy can we expect to offer?
- How are we going to deploy the technology is a sane and scalable fashion?
- What happens when we try to initially index N-million documents?
- Given known content size and volume, can we get away with triggers over change detection to support updates, at least at first?
- While Solr might give me more search punch, do user-rights and time-factored machine learning needs make Elastic a more likely candidate when augmented with X-Pack Security, Logstash, and Kibana?
- Do we understand the costs not only in terms of nodes, shards, and replicas but also in the care-and-feeding of said search infrastructure?
- What impact will these feature sets have on the existing day-to-day, non-search related development, unit testing, and automation testing?
- Can we support feature flags, user rights, adoption analytics, and A/B testing approaches? If so, to what degree?
- How does this search play into any mobile offering we have?
- Can I solve documents scattered across a variety of places with solutions provided by Citrix or Swiftype?
- Are we equipped to get out ahead of issues leveraging tools such as Xymon or New Relic?
- When does the newly hired data scientist arrive, and do you think she’d be okay with using lightweight NLP labeling for classifiers for now with an option for self-taught learning later?
- Hey, WHOA THERE BUCKAROO … is a Lucene-based search index good enough for what we need, or are we really talking about a dimensional data lake that might require something more along the lines of Hadoop &/or Spark like technologies?
- Dude, those last two bullet points above this one make me want to ask “are you sure you want to invest in an NLP pipeline” to augment your index ingestion? It’s cool if you do, but know it ain’t cheap.
And that’s just the infrastructure questions. If you possess similar survivor stories as I, you may also find yourself asking other groups within your organization different, more front-end type questions, such as:
- What the search results look like? Cards? Text blocks? Grids?
- Do we need to support work streams based on search results requiring the ability to save, export, and/or share searches.
- How well do our speech-to-text capabilities assert the correct search? Are they handled in a fashion similar to typos in a search bar?
- Are our users comfortable with more advanced query constructs? Will end users wig-out on wildcards AND|OR|NOT operands (see what I did there)?
- On implementing facets and filters, how and which elements of the index do we surface?
- Are we exposing the underlying API of the search engine, or wrapping them up in our own abstractions?
- Do the customer’s immediacy and re-indexing expectations align with our current operational realities?
- Do we create an interface to expose the underlying graph of relationships and associations between documents for customer tweaking?
- Is there a need for audit reports based on searches and document interactions based on search results.
- Pagination? Printing? Sorting (though we prefer they understand TF-IDF scoring)?
- Why can’t we replace all searches and filters in the app with this technology?
There are plenty more questions you can ask related to both the front and back-end concerns, but you get the picture.
4.5 — The Backlog
As we get questions answered, as we become comfortable with the data we’ve collected, as we move past your initial conversations, our attention will inevitably turn towards your backlog.
Not only for the interactive experiments I explained in section 3 above, but for all the fun infrastructure stuff that happens in the course of the continuous delivery of features for a large, enterprise search solution supporting AI assisted full-text search of digital assets and beyond.
In other words, initially, I think I might initially light-up a backlog of Epics along the lines of:
- initial experiments
- infrastructure
- indexing
- APIs
- user interface
You may organize it all differently. That’s fine. One recommendation I might make is that however you arrange the work, that you consider equipping each Epic with a measurable hypothesis. Stolen straight out of the Lean Startup playbook, this approach also affords your organization with yet more touch points to determine if you need to persevere or pivot.
What this also means is that the Features we file under these various Epics should also be measurable milestones. For example, under our ‘indexing’ Epic, I might initially set it up with these four Features:
- Build an indexer for moving data from the primary SQL data store to the search index; ensuring we start with change detection out-of-the-gate (none of this triggers crap).
- Create services that ensure CRUD operations are reflected in the search index.
- Containerize/Script the process of implementation of the indexer and update services.
- Leave room for augmenting ingestion using various NLP tactics. For example, word2vec is interesting in terms of getting past basic contextual hurdles.
Similarly, I might consider the following Features under our ‘user interface’ epic:
- Accept a search query
- Render the search results
- Limit search results by filters
- Save, recall, and share search queries + filters
- Allow limited export of search results
For all of our Features — and I know you know this but I’m going to say it anyway — we of course will want to create very small Product Backlog Items, hopefully constructed along the INVEST principle to ensure their timely completion within a continuous delivery paradigm.
If you’re like me, you can test out how well your backlog organization is working out by running Kanban instead of Scrum for Sprint 0 and/or your ‘experiments’ epic. I’ve also found this approach excellent for introducing new teams to Agile.
Oh, and one other thing … and it’s a big thing … you need to continually emphasize to your team this one key tenet when working with search:
While this is true for any effort, because of the ubiquity of search, it is easy to run into debates with developers and stakeholders alike because they unconsciously bring their own biases into conversations not well equipped with persona and user journey related to search, especially in terms of what happens just immediately before and after the search.
Useful URLs
Here are some additional resources you may find useful in case you too find yourself thrust into a search initiative.
Blog posts I’ve written based on some of my search experiences
- The Convergence of Search & Machine Learning is already here.
- Why it pays to INVEST in user stories
- Sometimes, a feature toggle may not be enough …
- Software delivery is a lot like Pizza Delivery
- Some methods in persona creation I learned from singing opera
Search Technologies I’ve worked with
NLP/NLG Tools I’ve tinkered with
- Spacy
- Azure Cognitive Services
- NLTK — Natural Language Toolkit
Speech-to-Text services I’ve experimented with
- Google Cloud Speech-to-Text
- Transcribe via Amazon
- IBM Speech-to-Text
Books I’ve read on Search
- Marti Hearst — Search User Interfaces
- Enterprise Search — Martin White
- Peter Morville — Search Interfaces
- Designing the Search Experience — Tony Russell-Rose, Tyler Tate
- Jeff Patton — User Story Mapping: Discover the Whole Story, Build the Right Product
Books I’ve read on delivering value helpful to Search & other initiatives
- Lean Startup
- Lean Enterprise
- Lean Analytics
- Sprint: How to Solve Big Problems and Test New Ideas in Just Five Days
- The Phoenix Project