
TL;DR — How I might improve the recommender system used by Glassdoor so I no longer receive suggestions for ‘meat market manager’ positions.
I’ve heard it suggested that search and recommendations are similar solutions, but not the same, as the latter sentiment serving as a call to action. I think some of my past interactions with Glassdoor may be proof of this.
For example, when I enter “Product Manager” into the Glassdoor search page, I am generally satisfied with what appears to be your typical TF-IDF generated list of opportunities in the Raleigh-Durham area, enough so to save it as an ‘Alert’ notification. So imagine my surprise when I received the following recommendation in my inbox:

Amusing as this “… exciting new opportunity that seems like a perfect fit” was, the only action this recommendation inspired was to reach out to Glassdoor on Twitter, who in turn explained that this recommendation was triggered by a keyword search on the word “manager.”
Hi, thanks for the clarification! I sent this info to our PMs too, so we can continue to improve our experience! Our system identifies keywords, so sounds like it chose the word "Manager" from your profile & matched a job with that keyword. Thanks for the feedback! – Octavia
— Glassdoor (@Glassdoor) July 3, 2018
Without additional data, I’m guessing that such a simple keyword search might also explain why I’ve received more than my fair share of not-so-desired recommendations for “Project Manager” from a variety of sources.
So how might I solve this use case as a “Product Manager?” Good question, let me respond with the types of recommender systems available, along with some of their related approaches and then let you decide.
Content-based filtering
Also known as cognitive filtering, content-based filtering helps make recommendations based on descriptive attributes associated with a given item. We see this manifested in a couple of ways, one via explicit facets associated with something we might be interested in, the other inferred.
Explicit Behavior
I’ve found that similar search-driven notifications from LinkedIn don’t include some of the sub-optimal suggestions I’ve received from Glassdoor, such as ‘Channel Sales Program Manager’ or ‘Airfield Engineer/Project Manager.’
I suspect one of the ways LinkedIn ensures higher quality recommendations is by explicitly asking me “What job titles are you considering?” in my profile.
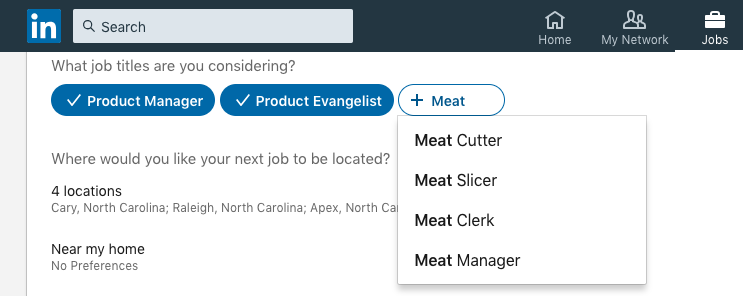
Basically, the more clarity I provide their system through manual entry of titles of interest, the better the filtering of results I receive.
Implicit Behavior
If you purchase a new laptop online from BestBuy, what do you see the next time you log in? Yup, you guessed it, recommendations for a keyboard, cases, and other common accessories. The trick is, of course, figuring how to maintain associations between items. For example, if I buy a MacBook then it’s probably less enticing if the system recommends a Microsoft Mouse than one manufactured by Apple.
In the case of Glassdoor, a user can both save and apply for positions. The system can also collect an individual’s current job title and skillsets via manual profile edits and via a resume upload.
To their credit, Glassdoor does a very good job of this in following-up emails based on my save and apply behaviors. What I might also suggest is recommendations for resume services for those who upload a CV for the first time, or perhaps those uploads that fail horribly when tested against a grammar checker.
Hmm, now that I think of it, perhaps this is a good chance to partner with a service like Grammarly, where Glassdoor would receive a % of revenue from new customers referred via their resume recommendations?
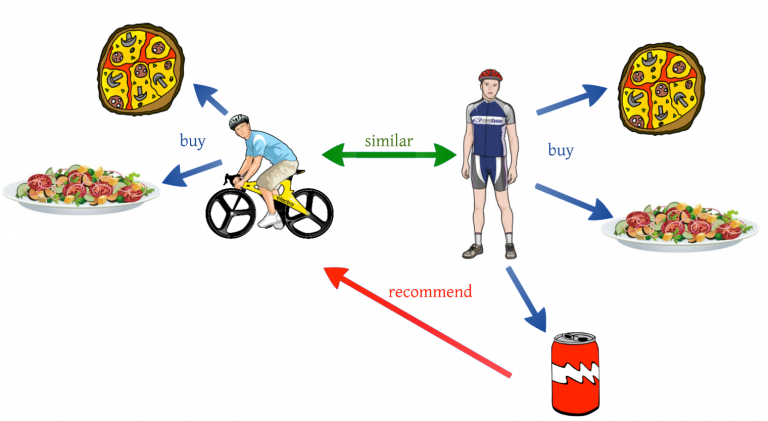
Collaborative filtering
Sometimes referred to as social filtering, this collaborative method to recommendations is built on the premise that birds of a feather tend to flock together. However, as this metaphor implies, you’re generally going to get better results with a larger flock that enjoys some degree of applicable diversity. Unfortunately, such a corpus isn’t always available on a cold start.
Comprehensive Guide to build a Recommendation Engine from scratch
Challenges aside, this is where much I find the area of recommender systems incredibly exciting, as this is where we’ve seen some clever applications of machine learning employed.
Neighbor-based approach
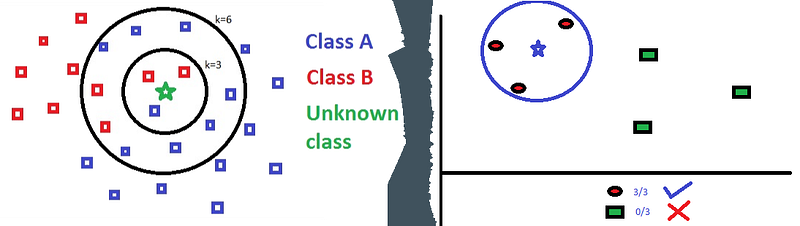
Ever get a recommendation from a movie or streaming service that says “what others like you are watching?” In some cases, it means that the recommender system is leveraging a data science technique to identify who your neighbors are, and what they like.
One such approach is k-Nearest Neighbors, where predictions are made for an ‘Unknown Class’ by searching through the entire training set for the K most similar instances (the neighbors) and summarizing the output variable for those K instances.
&
From an operational point of view, this is not a hard approach to implement as it is non-parametric, meaning no assumptions are made about underlying data distribution as the model structure is determined from the data. The downside is that this approach can be computationally expensive, specifically, it can be a memory pig.
That aside, it would be interesting to find out if systems like Indeed, LinkedIn, and Glassdoor employs this approach to serve-up candidates to those organizations and recruiters posting job openings … as I’m sure the hiring manager at the Piggly Wiggly would probably prefer candidates other than myself for their deli counter.
Item-to-Item Approach
This approach inverts “what are my neighbor’s saying?” techniques by instead focusing on the similarities the items being recommended for consumption.
Amazon makes heavy use of an item-to-item collaborative filtering approach so whenever you buy/look at an item, recommending items you might want to purchase based on our selected item’s related neighbors. They do this in part because it works, but also in part because there is a much smaller corpus of data at the item level than their millions of customers.

This is where you want to enlist the help of your local data scientist as they can guide you towards implementations such as the Pearson correlation coefficient, with the result a near perfect correlation between a ‘product manager’ and ‘product owner,’ rather than ‘meat market manager.’
Classification-based approach
Similar in concept to the Neighbor-based approach, classification goes a bit deeper by vectorizing attributes associated with an individual and items.
Once data is mapped into vectors, there are a variety of data science techniques one can apply, and within each technique, various methods that can be explored (Again, yet another compelling reason to treat your local data scientist to lunch from time-to-time).
For example, there is matrix decomposition, a method of turning a matrix into a product of two matrices. Visit the Wikipedia page on this topic, and you’ll see that this is a whole science in and of itself, but one worth investigating as it is an approach we see utilized by Spotify and Netflix.
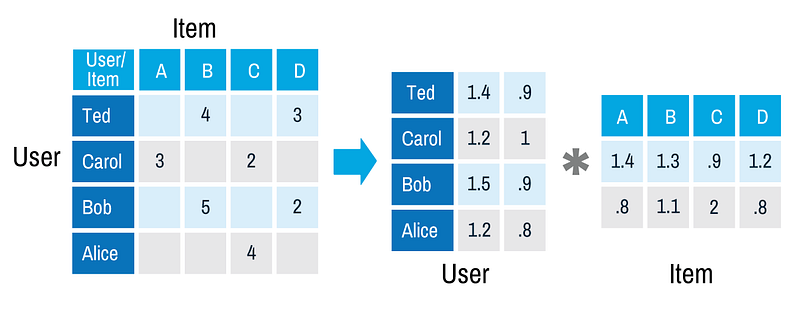
A vector space another model we see often employed in advanced search and NLP pipeline implementations is cosine similarity, which is basically a proximity measure of the cosine of the degrees distance between two points which are sometimes tempered when there are multiple dimensions involved.
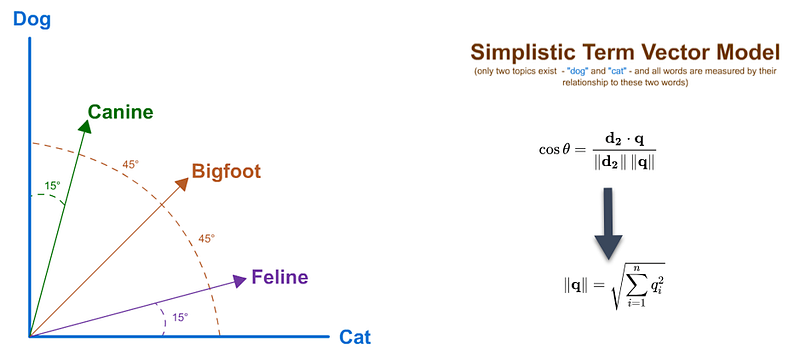
Regardless of how one decides the model their data, from a product manager point-of-view, I’m simply trying to point out that perhaps Glassdoor needs to consider such approaches so they can at least associate synonymous matches to product managers, such as product owner or product evangelist … rather than the less-desired recommendations for a project or program manager.
Hybrid Recommender Systems
This is a recommender system that combines one or more approaches, including partnering collaborative filtering with content-based filtering. Netflix is a good example of hybrid recommender systems, making recommendations by comparing both the watching and searching habits of similar users in combination with movies that share similar characteristics the target user has identified as highly rated.

In the case of Glassdoor, my thought would be towards a hybrid recommender for jobs of interest. I’d probably first make sure that any email alerts based off a search are taking into account the rank order, after first making sure we’re just not encountering the downsides of a LIKE ‘%manage%’ SQL search scored against contextless bag-of-words.
I might also want to get a quick glimpse of the tokenizers and analyzers in place just to ensure we don’t have a ‘garbage-in problem.’ I’d then explore whatever “More Like This” functionality exists in my current search system.
Once I’ve got the search issues squared away, I’d pursue a path of experimentation with iterative increments that prove (or disprove) the effectiveness of various filter, facet, and rank applications … probably first moving in the direction of comparing my neighboring peers who have ‘rated’ various job offerings in the form of a ‘save’ or ‘apply’ actions to my own … perhaps reducing computational overhead by graphing against the top-n items versus the entire corpus. Anything past this in the initial releases strikes me as BFUD … IMHO.
My hypothesis is that stronger recommendations devoid of non-sequiturs would result in more email reads, and from that, more job posting visits which subsequently increase ‘apply’ behaviors. In turn, this would empower Glassdoor to provide an even greater value proposition to those customers paying to place job offerings.
YMMV